Data onboarding
Transferowanie zbiorów danych do Twojej przestrzeni AI
Przed rozpoczęciem subskrypcji GPU masz możliwość przygotowania swojego zbioru danych, aby był gotowy w dniu uruchomienia. Jeśli istnieje taka potrzeba, możemy przygotować pod Kubernetes typu data proxy z wysokoprzepustowym połączeniem internetowym, co pozwoli na transfer zbiorów danych bezpośrednio do Twojej przestrzeni AI, którą jest Kubernetes Persistent Volume Claim.
Dlaczego warto przechowywać dane w PVC?
Przechowywanie zbiorów danych, na przykład w bucketach obiektowych S3, jest wygodnym i opłacalnym wyborem dla danych zimnych (cold data). Jednak podczas subskrypcji prawdopodobnie będziesz chciał w pełni wykorzystać procesory GPU. Dlatego niezbędny jest optymalny sposób dostępu do danych w przestrzeni AI.
Na poziomie DGX montujemy dedykowany system plików z macierzy Pure Storage FlashBlade za pomocą NFS over RDMA (RoCEv2), używając dedykowanych sterowników dostawcy certyfikowanych przez NVIDIA o nazwie GPUDirect Storage. Dzięki temu osiągane są najniższe możliwe opóźnienia między DGX a macierzą, co jest kluczowe dla typowego trenowania lub przetwarzania zbiorów danych, zazwyczaj zawierających tysiące lub znacznie więcej małych obiektów. Gwarantuje to, że pamięć masowa nie jest wąskim gardłem w procesach akcelerowanych przez GPU.
Na bazie takiego dedykowanego punktu montowania NFS tworzony jest Persistent Volume Claim i dodawany do Twojego projektu na platformie workload, takiej jak Run:ai, dzięki czemu konsumpcja przez różne zadania (workloads) jest dostępna. W przypadku poda data proxy, punkt montowania znajduje się w ścieżce /data.
Mimo to, źródło danych w postaci bucketu S3 nadal jest opcją w niektórych przypadkach, ale zazwyczaj daleką od optymalnej, której nie możemy rekomendować w architekturze F.I.N.
Data proxy
Dostęp
Publiczny dostęp SSH zostanie Ci przyznany przez nasz zespół po udostępnieniu nam Twojego klucza publicznego. Aby osiągnąć optymalną wydajność transferu i zapewnić bezpieczeństwo danych, zalecamy format Ed25519.
Przypadki użycia
Data proxy jest przygotowane do pracy zarówno jako inicjator połączenia (klient), jak i jego serwer (SFTP/SSH), w zależności od Twoich potrzeb. Oto przykładowe przypadki użycia wraz z odpowiednimi diagramami:
pobieranie danych z Twojego bucketu S3, którego punkt końcowy (endpoint) jest dostępny z Internetu przy użyciu Twoich kluczy;
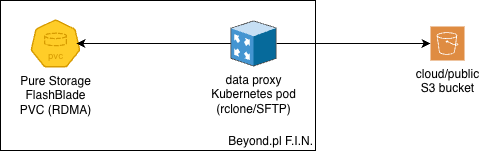
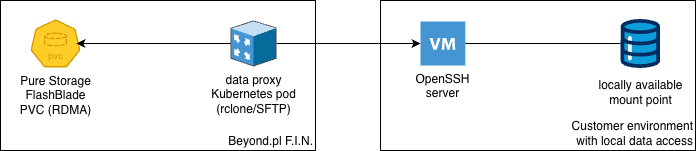
możesz również połączyć się ze swoim serwerem SSH/SFTP za pomocą pary kluczy SSH, aby pobrać dane;
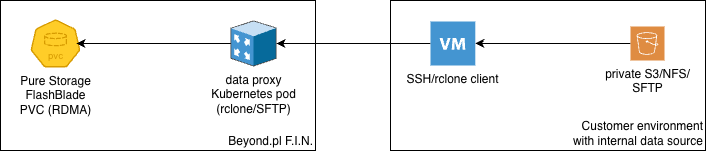
lub po prostu połączyć się ze swojego serwera do data proxy przy użyciu SSH/SFTP (również z parą kluczy), aby przetransferować dane dostępne tylko z Twojej sieci lokalnej.
Narzędzie do transferu
W zależności od przepustowości Twojego łącza sieciowego, użycie samych protokołów SCP lub SFTP, a nawet rsync, prawdopodobnie nie zapewni wystarczającej równoległości, aby w pełni ją wykorzystać; szczególnie przy ogromnej liczbie małych obiektów. Proponujemy Rclone - “szwajcarski scyzoryk” w zakresie synchronizacji danych między dziesiątkami typów przestrzeni.
Jeśli nie jest to dla Ciebie odpowiedni wybór i masz już inne preferowane narzędzie, daj nam znać przed utworzeniem poda, abyśmy mogli je dla Ciebie dołączyć.
Rclone - konfiguracja
Możesz użyć polecenia rconfig config, aby rozpocząć konfigurację zdalnych punktów końcowych, takich jak SFTP (używając serwera OpenSSH) lub S3 w sposób interaktywny. Niemniej jednak, zalecane może być dodanie do konfiguracji pewnych dodatkowych parametrów dostrajających, jak pokazano poniżej.
Umiejscowienie konfiguracji i użycia rclone – czy to na F.I.N. data proxy, czy na serwerze w Twoim środowisku – zależy od wspomnianego wcześniej przypadku użycia.
Oto kompletne szablony punktów końcowych do zapisania w pliku konfiguracyjnym ~/.rclone/rclone.conf.
[s3]
type = s3
provider = Other
access_key_id = <your_key>
secret_access_key = <your_key>
endpoint = <s3_address>
acl = private
[sftp]
type = sftp
host = <ssh/sftp address>
user = <user>
key_file = ~/.ssh/id_ed25519
shell_type = unix
sha1sum_command = sha1sum
#disable_hashcheck = true
md5sum_command = none
Prosimy o zweryfikowanie specyficznej konfiguracji protokołu w dokumentacji Rclone. Pamiętaj o dostarczeniu klucza SSH w skonfigurowanej ścieżce. Zalecamy wygenerowanie nowej pary kluczy do połączenia między lokalizacjami – gdy zdalny punkt Rclone to SFTP – specjalnie do tego celu. Polecenie ssh-keygen bez żadnych dodatkowych parametrów na data proxy generuje już optymalny wynik.
W przypadku protokołu SFTP możesz zauważyć obciążenie procesora wynikające z obliczeń sum kontrolnych. W takim przypadku warto rozważyć wyłączenie sprawdzania sum kontrolnych za pomocą zakomentowanego parametru disable_hashcheck.
Rclone - użycie
Poniższe przykłady pokazują parametry, które uznaliśmy za optymalne przy wykorzystaniu wydajnego procesora. Zachęcamy do eksperymentowania z wartościami, aby dopasować je do Twojego środowiska.
Jako wskaźniki źródła lub celu w poleceniu rclone można podać zarówno aliasy zdalnych punktów końcowych zawarte w plikach konfiguracyjnych, jak i ścieżki lokalne. Wyjaśniając, Rclone używa własnego klienta SSH, więc wymagane jest zawarcie pełnej konfiguracji dla zdalnych punktów SFTP w pliku konfiguracyjnym Rclone.
Z publicznego bucketu S3 do lokalnego punktu montowania PVC:
rclone copy \
--no-check-certificate \
--transfers 128 \
--checkers 128 \
--fast-list \
--multi-thread-streams=4 \
--buffer-size=32M \
-P \
s3:bucket/path /data/dataset
Z S3 dostępnego (i tym samym uruchamianego) z Twojego serwera przez Twoją sieć lokalną do punktu montowania PVC na F.I.N. data proxy:
rclone copy \
--no-check-certificate \
--transfers 128 \
--checkers 128 \
--fast-list \
--multi-thread-streams=4 \
--buffer-size=32M \
-P \
s3:bucket/path dataproxy_sftp:/data/dataset
Usuń opcję --no-check-certificate z powyższych przykładów, jeśli używasz zaufanego łańcucha certyfikatów.
Ze ścieżki systemu plików dostępnej (i tym samym uruchamianej) z Twojego serwera do punktu montowania PVC na F.I.N. data proxy:
rclone copy \
--transfers 128 \
--checkers 128 \
--multi-thread-streams=4 \
--buffer-size=32M \
-P \
/local/path/to/dataset dataproxy_sftp:/data/dataset
Ponieważ oczekuje się, że transfer zbioru danych często będzie długotrwały, warto uruchomić narzędzie w programie screen: screen -S rclone - aby utworzyć nową sesję; screen -r rclone - aby podłączyć do niej konsolę; ctrl + A + D - aby się od niej odłączyć.
W przypadku przerwania transferu nie martw się; możesz łatwo uruchomić operację rclone copy ponownie. Rclone porówna źródło z celem i skopiuje do miejsca docelowego tylko pominięte lub błędnie skopiowane pliki.
Oba zaprezentowane powyżej protokoły – SFTP i S3 (wykorzystujący HTTPS) – używają szyfrowania, więc Twoje dane są bezpieczne podczas transferu przez Internet. Jeśli jednak Twoje dane nie wymagają szyfrowania w warstwie transportowej – na przykład są to dane publiczne lub dedykowane połączenie jest już uważane za bezpieczne – istnieje możliwość użycia nieszyfrowanego serwera Rclone WebDAV i klienta między lokalizacjami. Ze względu na ryzyko bezpieczeństwa i wątpliwą poprawę wydajności (obecne procesory odciążają popularne algorytmy szyfrowania, takie jak AES 256), nie publikujemy tego przykładu. Pamiętaj o tym podczas rozważania protokołu transferu.
Zakończenie transferu danych
Gdy transfer danych zostanie zakończony, prosimy o utworzenie zgłoszenia (ticket request). Nasz zespół wyłączy instancję data proxy i udostępni PVC Twojemu projektowi F.I.N., aby mogło być używane jako źródło danych w wybranych przez Ciebie zadaniach (workloads).